OWL-ViT - Open-Vocabulary Object Detection
This is my learning notes for the OWL-ViT (v1 & v2) model. When I first read their paper, I mixed the OWL up with some parts of DETR. Note my past confusion here.
Object detection has traditionally been limited to fixed-category models, where detectors are trained to recognize a predefined set of objects. However, real-world applications demand open-vocabulary detection, where a model can identify objects it has never explicitly seen during training. OWL-ViT (Open-World Localization with Vision Transformers) is a step toward this goal, leveraging Vision Transformers (ViT) and contrastive learning to create a scalable and simple detection model that works with natural language queries.
OWL-ViT (v1)
Model Architecture
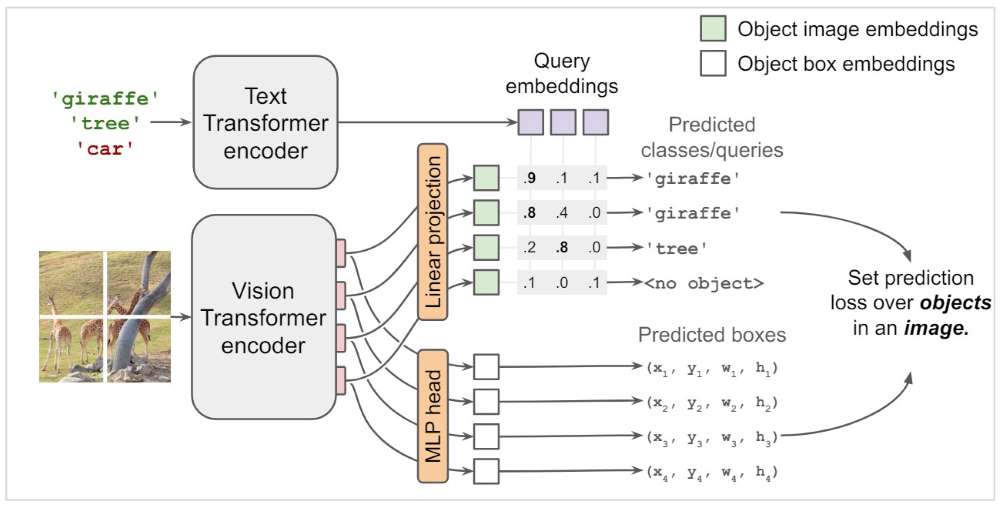
Unlike traditional object detectors, OWL-ViT does not use region proposals (like Faster R-CNN) or object queries (like DETR). Instead, it modifies a standard Vision Transformer (ViT) by removing the token pooling layer and adding:
- A bounding box regression head (MLP) that predicts object locations.
- A classification head (linear projection) that matches detected objects to text-based queries.
Each ViT token corresponds to a candidate object. If the ViT encoder outputs 256 tokens, the model can detect up to 256 objects in an image. This makes OWL-ViT simple yet effective—every token inherently represents both spatial and semantic features, allowing it to predict bounding boxes and labels simultaneously.
Training Methods
The key to OWL-ViT’s generalization lies in its two-stage training strategy:
- Contrastive Pretraining on Large-Scale Image-Text Data. The model learns to associate images and text descriptions through contrastive learning, similar to CLIP. This step enables it to understand a broad range of visual concepts, even for objects not explicitly labeled in detection datasets.
- Detection Fine-Tuning with Open-Vocabulary Classification. Instead of classifying objects into a fixed set of categories, the model learns to compare detections with text embeddings. This enables the model to generalize beyond a closed vocabulary—users can query it with free-form text, such as “a golden retriever” or “a red sports car,” and it will find relevant objects.
At inference time, the model does not require a fixed set of class labels; instead, it dynamically matches detected objects to the provided text queries.
How OWL-ViT Aligns Bounding Boxes and Object Labels
A crucial aspect of OWL-ViT’s design is how it ensures that bounding boxes and classification labels refer to the same object. Since each ViT token represents a spatial region, the same token is used:
- By the MLP head to predict a bounding box.
- By the linear projection layer to compute a classification score.
This creates a one-to-one alignment between bounding boxes and labels: The first ViT token produces the first object candidate, the second token produces the second, and so on. There is no separate object proposal step, making the pipeline straightforward and computationally efficient.
Comparing OWL-ViT and DETR
OWL-ViT might seem similar to DETR (Detection Transformer) since both use transformers for object detection, but they have fundamental differences.
In DETR, object detection relies on a fixed set of object query tokens that do not correspond to specific image regions. These object queries are learned embeddings that attend to different objects in the image dynamically through cross-attention in a Transformer decoder. This means that in DETR, the number of detected objects depends on the number of query tokens, not the number of ViT tokens.
In contrast, OWL-ViT does not use object queries or a decoder. Instead:
- Each ViT token directly represents an object candidate, meaning detection happens token by token.
- There is no separate attention mechanism between object candidates, unlike DETR’s query-to-image cross-attention.
Since OWL-ViT avoids object queries and a Transformer decoder, it is simpler and more direct in its approach.
Thoughts
OWL-ViT offers a simple and effective way to adapt Vision Transformers for open-vocabulary object detection. By leveraging contrastive pretraining, it generalizes to novel objects using text-based queries, making it useful for real-world applications where a predefined object list is impractical. Unlike DETR, which relies on object queries and a decoder, OWL-ViT’s one-token-per-object structure provides a clear and interpretable alignment between tokens and detections.
However, OWL-ViT is not a complete replacement for query-based models like DETR. DETR’s approach allows more flexibility, especially in complex images with overlapping objects. OWL-ViT, on the other hand, benefits from its modular and scalable design, making it an excellent baseline for open-vocabulary detection with transformers.
OWL-v2
OWLv2 uses a similar architecture to the original OWL-ViT model, but OWLv2 introduces several optimizations to make training more efficient.
The key innovations introduced in OWLv2 include:
- Token Merging to reduce redundant computations
- Objectness Scoring to prioritize high-confidence detections
- Efficient Implementation strategies for improved training throughput
- Self-training (OWL-ST) for massive-scale weakly supervised learning
Token Merging
Vision Transformers (ViTs) process images by dividing them into small patch tokens, which are individually analyzed. In deeper layers of the network, many of these tokens encode similar information, leading to redundant computations. Token Merging selectively fuses highly similar tokens, reducing the total number of tokens passed to deeper layers. This cuts down the computational cost without significantly affecting performance. Token Merging reduces memory usage and speeds up training by nearly 50%, allowing models to scale more efficiently.
Objectness Scoring
OWLv2 improves object detection performance with Objectness Scoring, a mechanism that filters out low-confidence detections during training. Instead of processing all detected objects, OWLv2 assigns an “objectness” score to each detected region. The top ~10% of highest-confidence detections are selected for training, while lower-confidence regions are ignored. This prevents the model from being overwhelmed by irrelevant detections or noisy bounding boxes.
Self-training at Scale
A groundbreaking feature of OWLv2 is its ability to self-train on large-scale weakly supervised data. The OWL Self-Training (OWL-ST) strategy enables massive scalability while improving generalization.
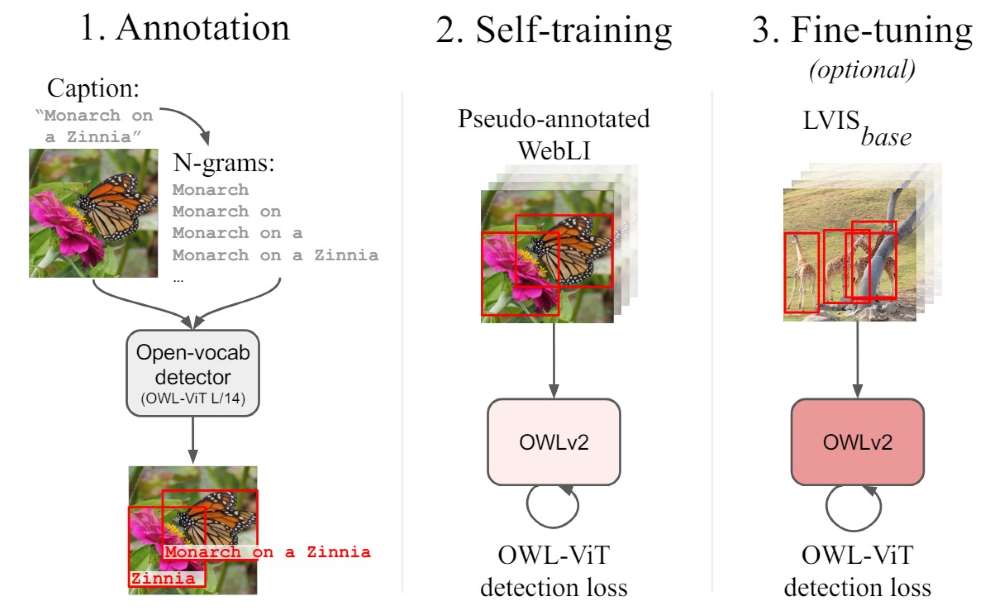
The OWL-ST includes three parts:
- Generating Pseudo-Annotations: An existing object detector generates pseudo-box annotations for images in web-scale datasets (e.g., images with captions but no explicit bounding boxes).
- Training on Pseudo-Labels: A new OWLv2 model is trained using these pseudo-annotations, learning to associate text descriptions with object regions.
- Fine-Tuning on Human-annotated Data (Optional): To further refine detection, the model can be fine-tuned on curated datasets like LVIS.
OWL-ST enables training on over 1 billion examples, improving detection for rare objects without costly human annotations. I believe this is the major reason of the improvement.
Thoughts
Just as large-scale data has improved language models, OWLv2 shows that detection performance continues to improve with more weakly supervised data. The paper [2] also mentioned that using a lower confidence threshold for the pseudo annotations and keeping more data yielded the best results. When we generate pseudo annotations for other tasks, we can mimic this approach by generating a huge number of weak samples instead of a small number of strong samples.
References
[1] Minderer, M., Gritsenko, A., Stone, A., Neumann, M., Weissenborn, D., Dosovitskiy, A., … & Houlsby, N. (2022, October). Simple open-vocabulary object detection. In European Conference on Computer Vision (pp. 728-755). Cham: Springer Nature Switzerland. https://arxiv.org/abs/2205.06230
[2] Minderer, M., Gritsenko, A., & Houlsby, N. (2024). Scaling open-vocabulary object detection. Advances in Neural Information Processing Systems, 36. https://arxiv.org/abs/2306.09683