Quantization Fundamentals
This is a learning notes of the online course Quantization Fundamentals with Hugging Face (https://www.deeplearning.ai/short-courses/quantization-fundamentals-with-hugging-face/).
The current model compression methods include pruning, knowledge distillation, and quantization.
- Pruning: simply remove layers in a model that do not have much importance on the model’s decisions. The removing strategy is based on some metrics, like the magnitudes of the weights.
- Knowledge distillation: train a student model, which is the target-compressed model using the output from the teacher model in addition to the main loss term.
- Quantization: represent model weights in a lower precision. Note we can either quantize the model weights and the activations (i.e. output of layers).
Dtype casting
Module casting in pytorch
target_dtype = torch.float16 # torch.bfloat16
model = model.to(target_dtype)
model = model.half() # float16
model = model.bfloat16() # bfloat16
torch.set_default_dtype(desired_dtype)
Module casting in huggingface
model_bf16 = BlipForConditionalGeneration.from_pretrained("Salesforce/blip-image-captioning-base", torch_dtype=torch.bfloat16)
Note that most LLM models are float32. If we quantize to float16, sometimes weights may be out of the range of the float16 (overflow). In this case, we need to quantize the model to bfloat16. bfloat16 has the same range as the float32, but less precision.
Linear Quantization
Linear quantization involves mapping floating point values to integers using a linear transformation characterized by a scale factor (s) and sometimes a zero-point (z), which adjusts for the offset.
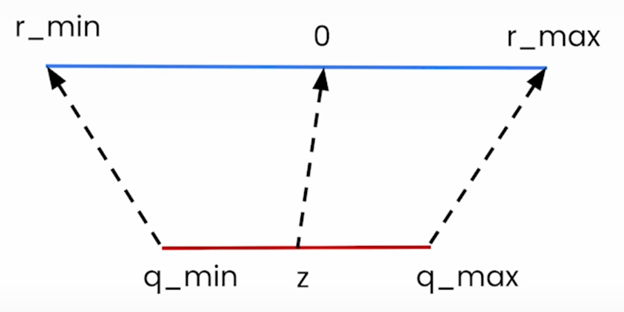
The quantization process can be expressed as: r=s(q-z) where
- r is the original value (e.g. FP32),
- q is the quantized value (e.g. INT8),
- s is the scale factor (e.g. FP32), and
- z is the zero-point (e.g. INT8).
This process is reversable, so that we can approximately convert back from the quantized integer value to the original value.
Quantization for inference
Quantized weights are not used directly for inference. Instead, they are dequantized back to floating-point values during computation. During inference, the quantized model work as follows:
- Load quantized weights. For example, quantized weights are stored as INT8.
- Dequantize on the fly. During matrix multiplication, weights are dequantized to FP32 using the precomputed
scaleandzero-point. - Compute with full precision. The actual inference (matrix multiplies) uses dequantized FP32 values, ensuring numerical stability.
dequantized_W = (quantized_W_int8 - zero_point) * scale
Y = torch.matmul(X, dequantized_W)
Quantization for training
Quantization Aware Training (QAT) is a technique used to mitigate the negative effects that can arise from quantizing a model, such as loss of accuracy. QAT simulates the effects of quantization during the training process. It trains the model in a way that controls how the model performs once it is quantized.
- During forward pass (inference), we use the quantized version of model weights (+ dequantization steps) to make predictions.
- During back propagation (updating model weights), we update original, unquantized version of model weights.
Simplified QAT training loop
float_W = torch.randn(4096, 4096, dtype=torch.float32, requires_grad=True)
optimizer = torch.optim.Adam([float_W], lr=1e-4)
for _ in range(steps):
# Forward: Quantize -> Dequantize
quantized_W = torch.round(float_W / scale)
dequantized_W = (quantized_W - zero_point) * scale
# Compute loss (e.g., cross-entropy)
loss = (x @ dequantized_W - y).square().mean()
# Backward (STE approximates d(loss)/d(float_W) ≈ d(loss)/d(dequantized_W) * 1/scale)
loss.backward()
optimizer.step()
optimizer.zero_grad()
# Optional: Recalibrate scale/zp every N steps
if step % 1000 == 0:
scale, zero_point = calibrate(float_W)
Quantization toolkit library from HuggingFace
Load model:
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("google/flan-t5-small")
model = T5ForConditionalGeneration.from_pretrained("google/flan-t5-small")
Quantize the model:
from quanto import quantize, freeze
quantize(model, weights=torch.int8, activations=None)
freeze(model)
Run inference:
input_text = "Hello, my name is "
input_ids = tokenizer(input_text, return_tensors="pt").input_ids
outputs = model.generate(input_ids)
Does Quantization Speeds Up Inference
Despite the computational overhead of dequantization, quantization often yields significant inference speed improvements through two key mechanisms.
First, memory bandwidth savings drastically reduce data transfer times: 4-bit weights occupy just 1/8th the memory of 32-bit floats, enabling faster loading from VRAM to compute units. For instance, a 7B model’s weights shrink from 28 GB (float32) to 3.5 GB (int4), cutting memory traffic by ~8×.
Second, optimized integer math leverages modern hardware advancements: dedicated low-precision accelerators (e.g., NVIDIA’s INT8 Tensor Cores) execute matrix operations up to 4× faster than float32 equivalents, while fused kernels like Marlin integrate dequantization directly into compute workflows, minimizing overhead.
More Recent Quantization Methods
- (only 8-bit) Dettmers, T., Lewis, M., Belkada, Y., & Zettlemoyer, L. (2022). Gpt3. int8 (): 8-bit matrix multiplication for transformers at scale. Advances in Neural Information Processing Systems, 35, 30318-30332.QLoRA
- (only 4-bit) Dettmers, T., Pagnoni, A., Holtzman, A., & Zettlemoyer, L. (2024). Qlora: Efficient finetuning of quantized llms. Advances in Neural Information Processing Systems, 36.
- Lin, J., Tang, J., Tang, H., Yang, S., Dang, X., & Han, S. (2023). Awq: Activation-aware weight quantization for llm compression and acceleration. arXiv preprint arXiv:2306.00978.
- Frantar, E., Ashkboos, S., Hoefler, T., & Alistarh, D. (2022). Gptq: Accurate post-training quantization for generative pre-trained transformers. arXiv preprint arXiv:2210.17323.
- Xiao, G., Lin, J., Seznec, M., Wu, H., Demouth, J., & Han, S. (2023, July). Smoothquant: Accurate and efficient post-training quantization for large language models. In International Conference on Machine Learning (pp. 38087-38099). PMLR.
- (up to 2-bit) Hicham Badri, & Appu Shaji. (2023). Half-Quadratic Quantization of Large Machine Learning Models. https://mobiusml.github.io/hqq_blog/
References
https://www.deeplearning.ai/short-courses/quantization-fundamentals-with-hugging-face/