Exploring the Studies Behind Sora
In this blog post, we’re diving into some fascinating research that forms the backbone of Sora. Beyond the well-known basics such as Transformer, Vision Transformer, and Stable Diffusion, there are other studies that play a big role too.
Here’s what we’ll cover:
- DiT: Scalable Diffusion Models with Transformers.
- ViViT: A video vision transformer.
- Patch n Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution.
DiT: Scalable Diffusion Models with Transformers
Diffusion models are a class of generative models that learn to generate data by reversing a diffusion process. This process gradually adds noise to the data until it reaches a pure noise distribution. Then, the model learns to reverse this process, starting from noise and gradually removing it to produce a sample from the target distribution. Diffusion models have been particularly successful in generating high-quality images by conditioning the reverse diffusion process on text or other forms of guidance.
Diffusion models like stable diffusion used to use U-Net as a backbone model to do the reverse process. Taking the high-noise image (in latent space) as the input, the backbone model cleans the noise a little bit and generates the low-noise image (in latent space). Now the DiT aims to improve the performance of diffusion models by replacing the commonly used U-Net backbone with a transformer.
DiT starts with a straightforward step. It divides the spatial representations of images into patches, and passes the sequence of patches into transformers, like Vision Transformer does. Then DiT proposes some unique block designs to fit the diffusion process.
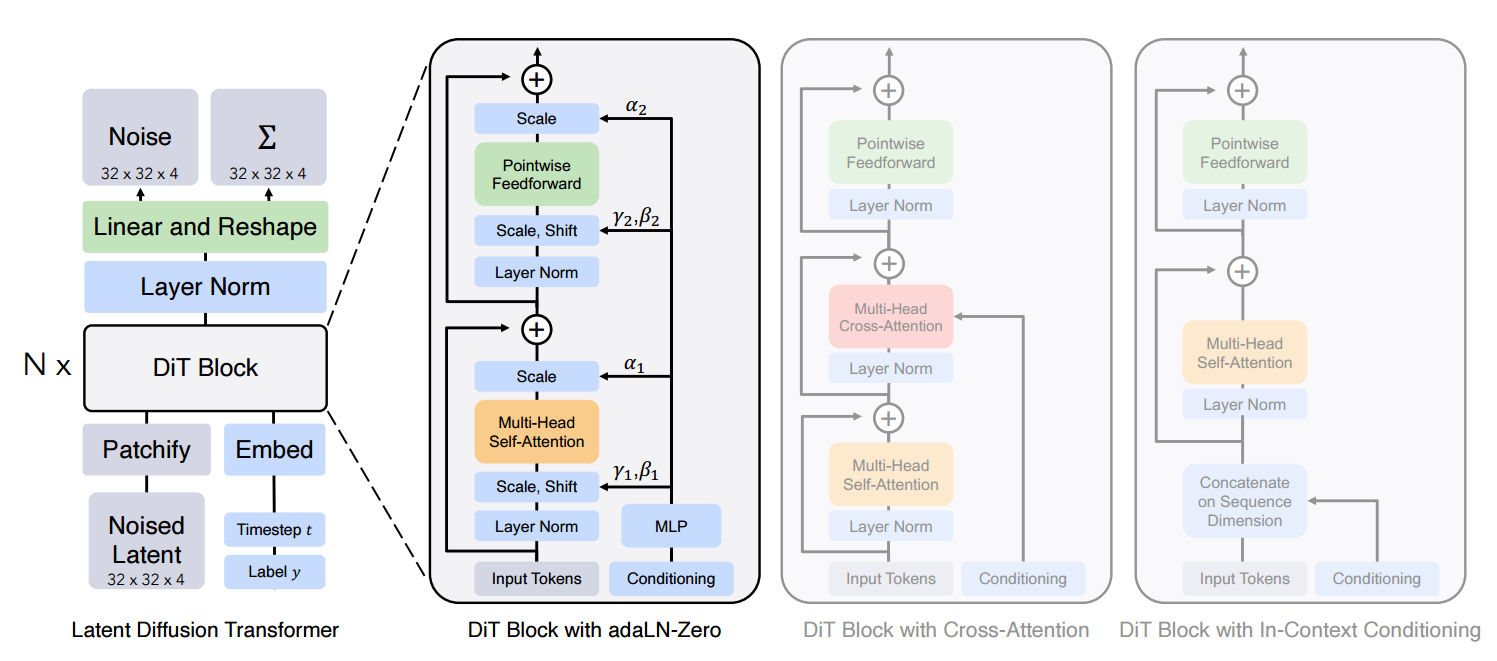
- In-context conditioning. We simply append the vector embeddings of conditioning (e.g. noise timesteps t and class labels c) as additional tokens in the input sequence, treating them no differently from the image tokens. The conditioning tokens are similar to CLS tokens in ViTs. After the final block, we remove the conditioning tokens from the sequence.
- Cross-attention block. We append the embeddings of conditioning tokens in the additional multi-head cross-attention layer. The cross-attention layer captures the interaction between the image tokens and the conditioning tokens.
- Adaptive layer norm (adaLN) block. We replace the standard layer norm layers in the vanilla transformer blocks with adaptive layer norm (adaLN). The adaLN is widely used in many GANs and U-Net diffusion models. The standard layer norm layer directly learns dimension wise scale and shift parameters. Here the adaLN regresses the scale and shift parameters (gamma, beta) from the sum of the embeddings of the conditioning tokens (e.g. noise timesteps t and class labels c). Note this is the conditioning mechanism that adds the least computation to the model.
- adaLN-Zero block. In addition to the scale and shift parameters in the adaLN block, we regress dimension-wise scaling parameters (alpha) that are applied immediately prior to any residual connections within the DiT block. We initialize the MLP to output the zero-vector for all alpha; this initializes the full DiT block as the identity function.
Vivit: A video vision transformer
The core idea of ViViT is quite straightforward, and it has some tricks in its variants. These clever tricks may also inspire us to develop other models.
Before I learned about ViViT, if you had asked me how to use Transformers with videos, I would probably have suggested chopping up each video frame into small pieces (patches), just like the ViT model does for images. Then, I would line up these pieces according to their position and the order they appear in the video. After that, I’d feed the sequence of these pieces into a standard Transformer model.
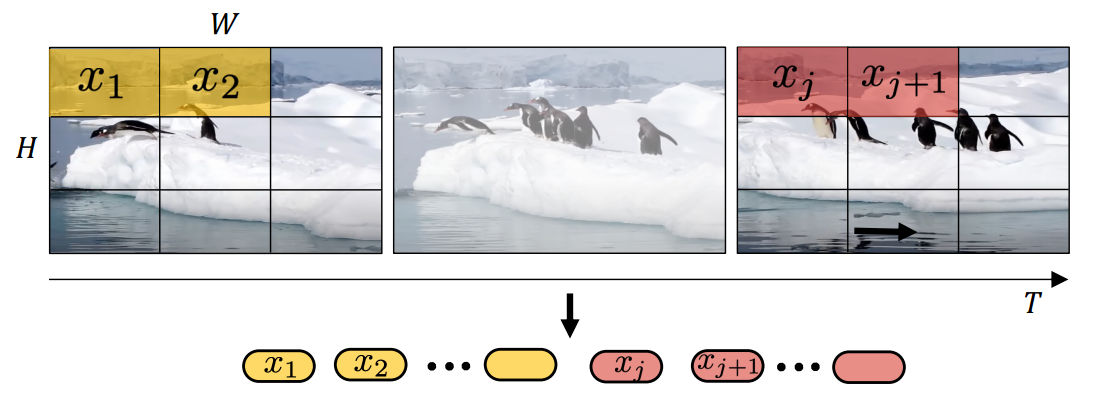
However, breaking down each video frame into tiny sections, or “patches,” creates an incredibly long list of these patches. This process requires a lot of computing power. ViViT introduces a smarter way to handle this by creating what are called spatial-temporal “tubes.” Think of each tube as a bundle that captures parts of the video across several frames in the same area. This approach significantly cuts down on the amount of computing work needed.
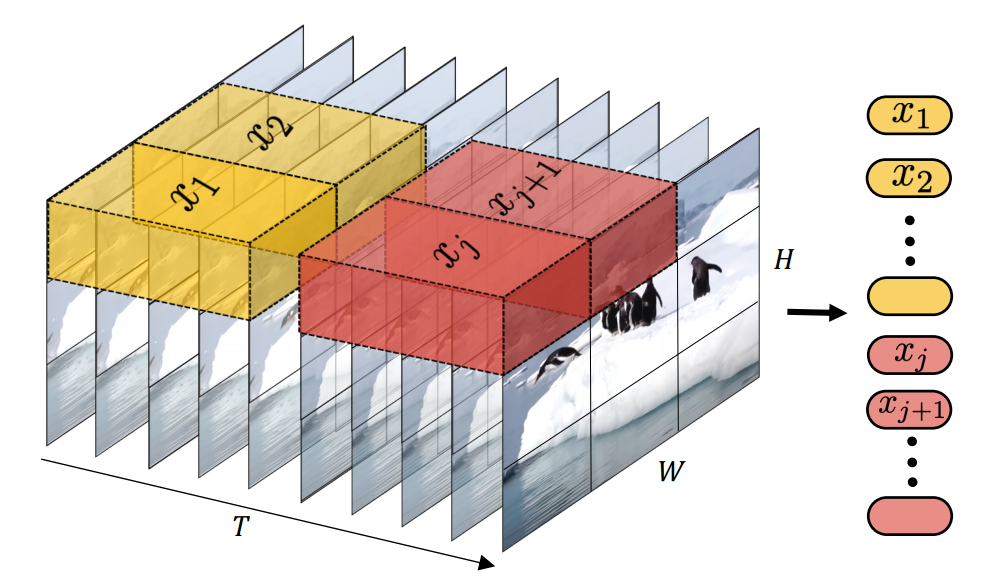
Here comes the clever tricks that the authors play. The authors of ViViT proposed 4 variants of Transformers to make the model more efficient.
Model 1: Spatio-temporal attention. This is the most basic approach. Like the ViT model that works with images, we pass the bundles of video parts through a regular Transformer model.
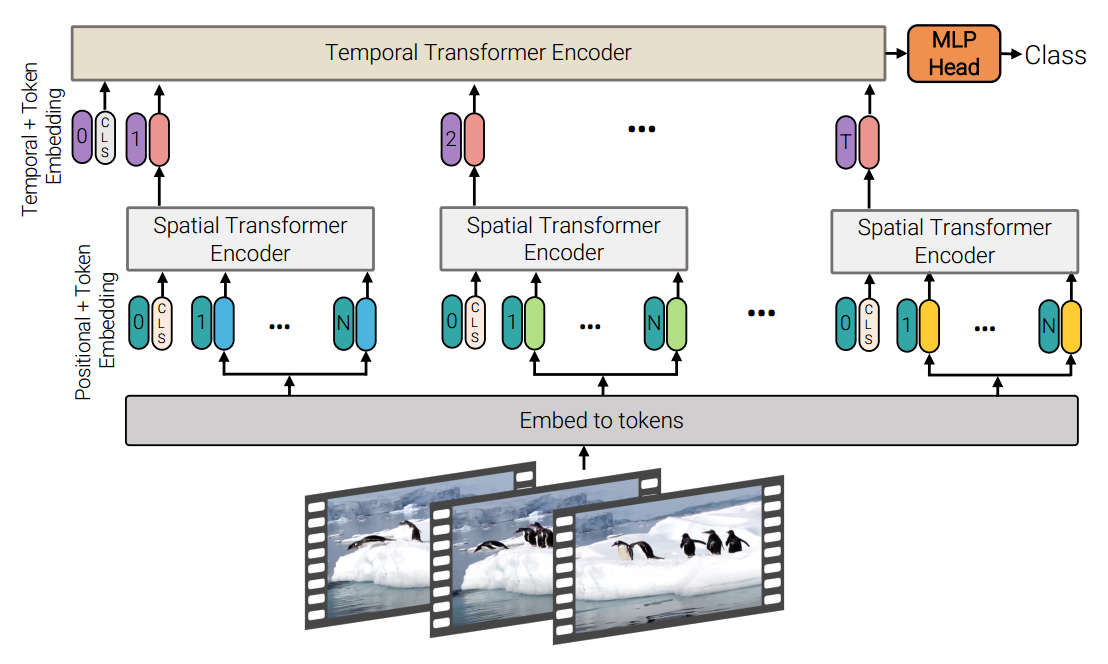
Model 2: Factorised encoder. In model 2, we first apply the attention among tubelets on the same temporal index but different spatial indexes, which is called Spatial Transformer Encoder. Then we take the outputs of the Spatial Transformer Encoder (either the CLS embeddings or the average poolings) and pass them to the Temporal Transformer Encoder, where the attention layers only impact the tubelets on the same spatial index but different temporal indexes. This method processes spatial information first, and then temporal information.
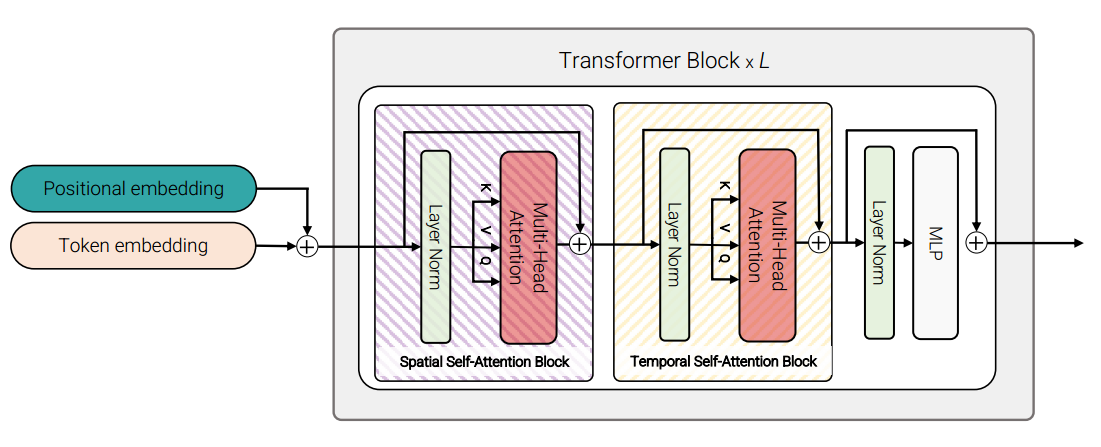
Model 3: Factorised self-attention. Model 3 has a similar idea to Model 2, but here, each step of processing for both space and time has its own special block within each Transformer block. This means data goes through spatial and temporal self-attention blocks in turns.
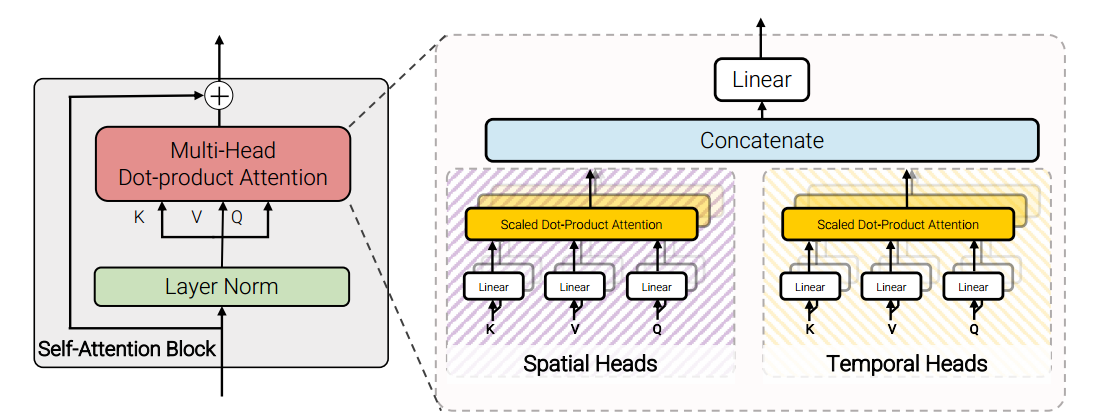
Model 4: Factorised dot-product attention. In Model 2 and Model 3, temporal and spatial blocks are stacked together sequentially. In Model 4, temporal and spatial blocks are in parallel. Tubelet embeddings go through temporal and spatial blocks side by side. Then the output of temporal and spatial blocks in the same layer will be concatenated.
By coming up with these different approaches, the creators of ViViT have made it much easier and more efficient to apply AI to videos.
Patch n Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution
NaViT is a technique that originated from ViT, but it presents a significant advancement by addressing a fundamental limitation in the vanilla ViT. The vanilla ViT needs to resize or pad images to a fixed resolution before training. It greatly hurt model efficiency. In contrast, NaViT (Native Resolution ViT) processes images in their native resolution and aspect ratio by employing a sequence packing technique during training, inspired by example packing in natural language processing (NLP).
Here’s an example of example packing in NLP:
- In a traditional setup, we would pad each sequence to the length of the longest sequence in the batch. Without example packing, we have something like this.
- Sequence 1: The cat sat on the chair [PAD] [PAD]. (8 tokens)
- Sequence 2: A quick fox jumps over the lazy dog. (8 tokens)
- With example packing (or sequence packing), instead of padding each sequence individually, we concatenate the sequences together into a single ‘pack’. The packed sequence would look like this.
- Combined sequence: The cat sat on the chair A quick fox jumps over the lazy dog. (14 tokens)
Borrowing the packing idea from NLP, NaViT treats images as sequences of patches, and packs them together. Images of different resolutions can be divided into patches of the same size and packed into a single sequence. This is the core idea in NaViT.
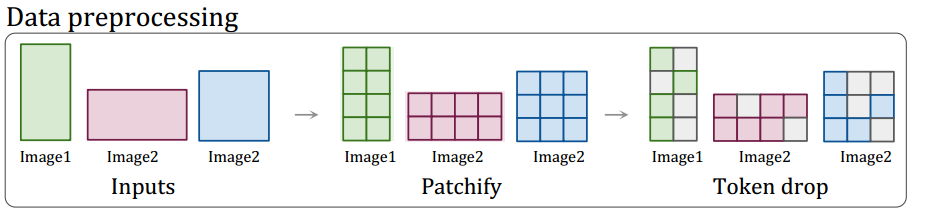
To enable Patch n Pack, NaViT makes both architectural changes and training changes.
-
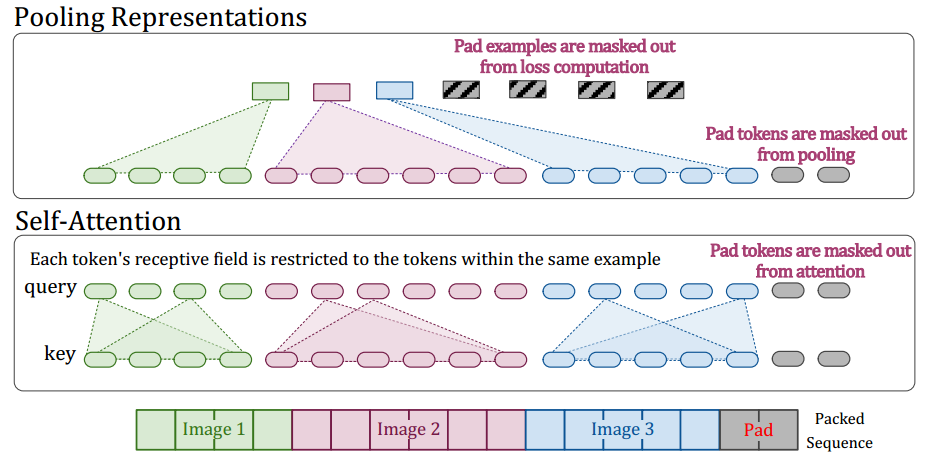
Masked self-attention and masked pooling. To prevent examples from attending to each other, additional self-attention masks are introduced. Only patches from the same images can do the self-attention and pooling together. This is a smart and necessary trick!
-
Factorized & fractional positional embeddings. To deal with diverse image sizes, NaViT uses separate x and y positional embeddings to accommodate variable resolutions and aspect ratios.
-
Continuous Token dropping. It allows for the random omission of input patches during training. It employs variable token-dropping rates for each image. This trick enables the benefits of faster throughput while reducing the train/inference discrepancy.
-
Resolution sampling. During training, NaViT either uses the original image or resampled pixels. This strategy is to keep the balance between high throughput and exposure to detail-rich images.
Reference
Video generation models as world simulators https://openai.com/research/video-generation-models-as-world-simulators
Peebles, W., & Xie, S. (2023). Scalable diffusion models with transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 4195-4205).
Arnab, A., Dehghani, M., Heigold, G., Sun, C., Lučić, M., & Schmid, C. (2021). Vivit: A video vision transformer. In Proceedings of the IEEE/CVF international conference on computer vision (pp. 6836-6846).
Dehghani, M., Mustafa, B., Djolonga, J., Heek, J., Minderer, M., Caron, M., … & Houlsby, N. (2024). Patch n’ pack: Navit, a vision transformer for any aspect ratio and resolution. Advances in Neural Information Processing Systems, 36.