LLM for Recommender Systems
Limitations of the current recommender systems
Summarized by [1], despite the existing success, most advanced recommender systems still have some limitations.
- Limited Textual Understanding: Due to model scale and data size limitations, existing deep neural network (DNN) models like CNNs, LSTMs, and pre-trained language models (e.g., BERT) cannot fully capture textual knowledge about users and items. This results in inferior natural language understanding and suboptimal prediction performance in various recommendation scenarios.
- Inadequate Generalization: Many recommendation systems are designed specifically for certain tasks and lack the ability to generalize to unseen tasks. For instance, an algorithm trained on a user-item rating matrix for movie ratings might struggle with making top-k movie recommendations with explanations, due to reliance on task-specific data and domain knowledge.
- Difficulty with Complex Decisions: While current DNN-based methods can perform well on tasks requiring simple decisions, like rating predictions or top-k recommendations, they struggle with complex, multi-step decisions. This includes recommendations that require multiple reasoning steps, such as planning a trip itinerary based on user preferences, popular tourist attractions, and specific constraints like cost and time.
Why is LLM a potential solution
Large Language Models (LLMs) have potentials for addressing the challenges in the recommendation systems for several reasons [1].
- Understanding and Generating Language: LLMs are really good at understanding and creating language that sounds human because they’re trained on a huge amount of text from different sources. This means they can better understand what people want and provide more natural responses.
- Generalization and Reasoning: LLMs are great at applying their knowledge to new situations they haven’t seen before and making logical connections. This makes them versatile and capable of tackling various tasks without needing specific training for each one. This is because they can use what they’ve learned from their vast training data to handle new challenges.
- Complex Decision Making: With techniques like “chain of thought” prompting, LLMs can break down complex problems into simpler steps. This is particularly useful for making complicated decisions, where understanding each step is crucial.
How does LLM work for recommender systems
Prompting LLMs for Recommender Systems
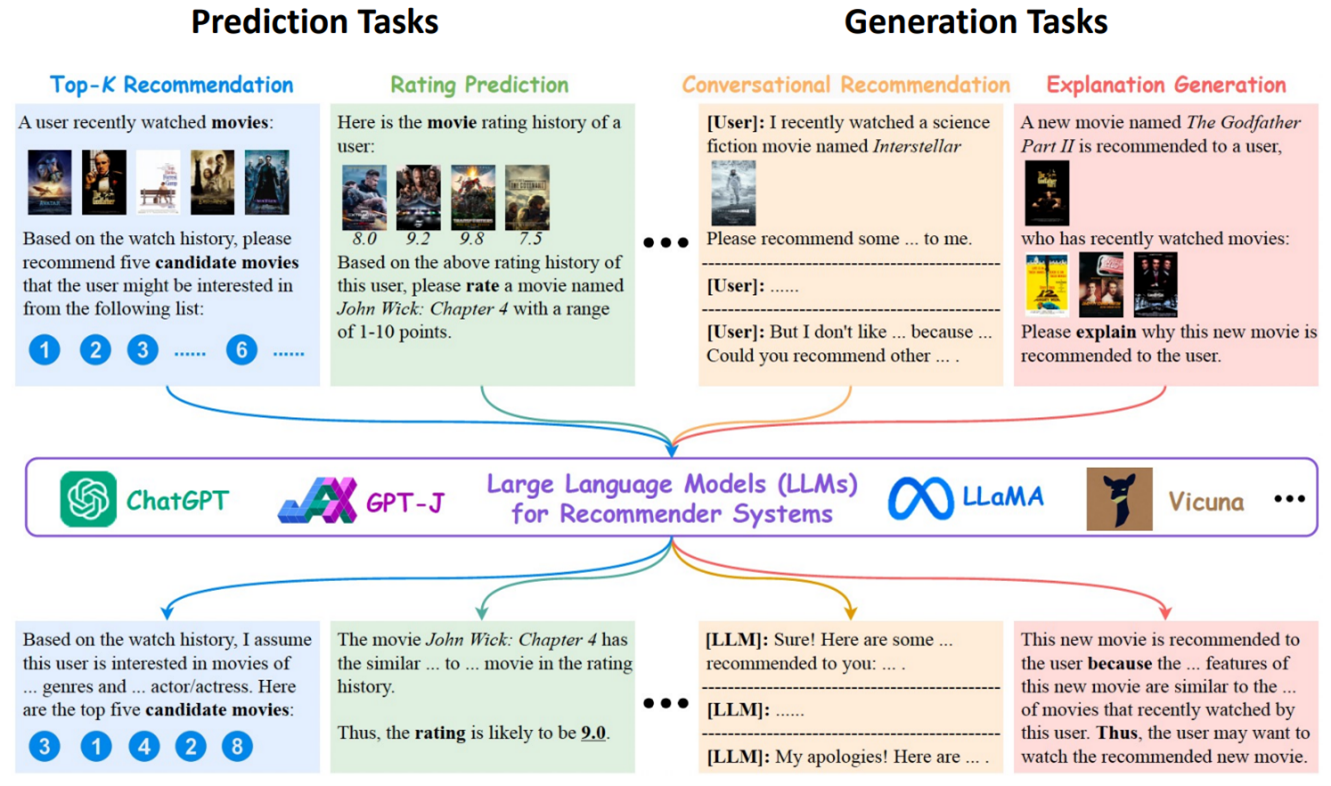
Prompting helps Large Language Models (LLMs) turn various recommendation tasks into language creation tasks. This matches what they were originally trained to do. The following are several ways to construct recommender systems by prompting LLMs.
- Top-K Recommendation [2]: By analyzing a user’s watch history, LLMs can recommend a list of top items that the user might be interested in. The LLM leverages its understanding of item features to generate a list of top five candidate items.
- Rating Prediction [3]: For rating prediction, the LLM assesses a user’s item rating history to predict how the user would rate a new item. The prediction is based on similarities between the new item and those in the user’s rating history, leading to a likely rating score.
- Conversational Recommendation [4]: In conversational recommendation, LLMs interact with users through prompts to understand their preferences and dislikes. This interaction helps in recommending personalized options based on the user’s responses.
- Explanation Generation [2]: For explanation generation, the LLM provides reasons why a recommended item matches the user’s previous viewing habits. The explanation involves drawing parallels between features of the new item and those of items the user has recently watched/used/purchased.
- In addition to the above 4, it’s also a good idea to generate personalized product descriptions for all possible products. It does not have to be for recommended items. The generated description can fit the user’s living habits better for an enhanced user experience.
For all the above-listed prompting methods, if the recommended items are new or not known by the base LLM, we can either finetune the base LLM on the documents of the items or add more item information to the prompt through retrieval augmented generation (RAG).
For reasoning-heavy tasks, like multi-step reasoning of user preferences based on the multi-turn dialogues in conversational recommendations, chain-of-thought (CoT) prompting is a powerful tool. CoT asks LLMs to break down complicated decision-making processes and generate step-by-step reasons. The following is a typical CoT promping summarized by [1]:
- [CoT Prompting] Based on the user purchase history, let’s think step-by-step. First, please infer the user’s high-level shopping intent. Second, what items are usually bought together with the purchased items? Finally, please select the most relevant items based on the shopping intent and recommend them to the user.
In some scenarios, we might already have a working recommendation system. Our goal could be to enhance the recommendations it provides, rather than replacing them entirely with new suggestions from LLMs. For instance, similar to the approach used in Chat-Rec [5], we can connect the LLMs and the traditional recommender systems. We pass the candidate items from traditional recommender systems to the LLMs and let the LLMs refine the final recommendation results.
Pre-training Transformers for Recommender Systems
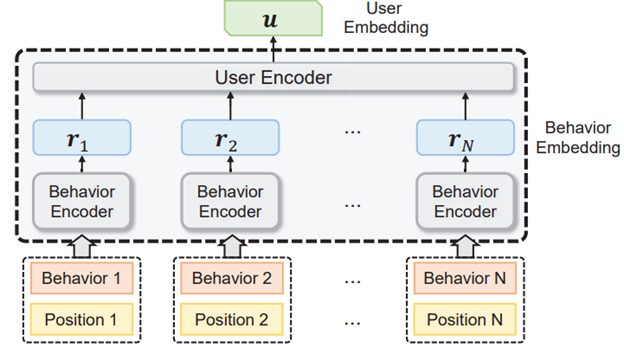
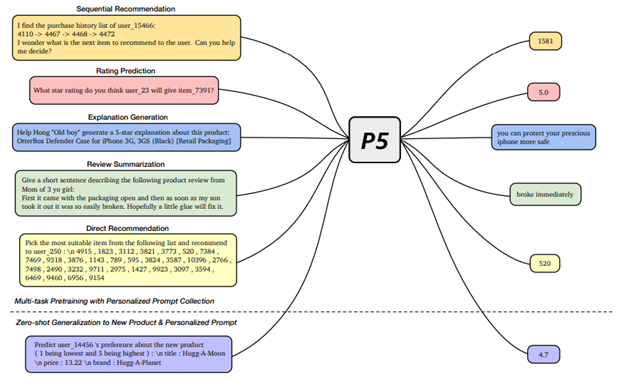
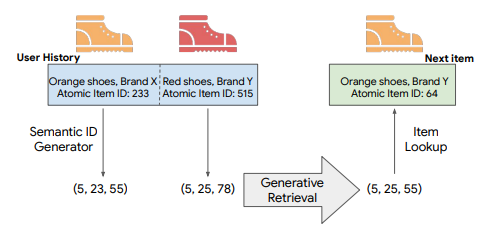
The authors of [1] call this method pre-training LLMs for recommender systems. However, I believe pre-training transformers is a more appropriate name. This method regards the user ids, item ids, or user behaviors as words in the natural language. The user ids, item ids, or user behaviors are indexed as unique tokens and then are used to train a transformer model. The representative works include PTUM [6], P5 [7] and TIGER [8]. The following Figure explains how these models works.
- PTUM treats a sequence of user behaviors as a sequence of unique tokens. The model is trained by two self-supervised tasks, Masked Behavior Prediction and Next K Behaviors Prediction.
- P5 treats user & item ids as unique tokens, and pretrains on an encoder-decoder Transformer model.
- Transformer Index for GEnerative Recommenders (TIGER) uses semantic ID to index the item ids. Similar items have the same ID on the first/second level. The TIGER also trains on an encoder-decoder transformer model.
References
[1] W. Fan et al., “Recommender Systems in the Era of Large Language Models (LLMs).” arXiv, Aug. 05, 2023. doi: 10.48550/arXiv.2307.02046.
[2] J. Liu, C. Liu, P. Zhou, R. Lv, K. Zhou, and Y. Zhang, “Is ChatGPT a Good Recommender? A Preliminary Study.” arXiv, Oct. 27, 2023. doi: 10.48550/arXiv.2304.10149.
[3] W.-C. Kang et al., “Do LLMs Understand User Preferences? Evaluating LLMs On User Rating Prediction.” arXiv, May 10, 2023. doi: 10.48550/arXiv.2305.06474.
[4] X. Wang, X. Tang, W. X. Zhao, J. Wang, and J.-R. Wen, “Rethinking the Evaluation for Conversational Recommendation in the Era of Large Language Models.” arXiv, Nov. 02, 2023. doi: 10.48550/arXiv.2305.13112.
[5] Y. Gao, T. Sheng, Y. Xiang, Y. Xiong, H. Wang, and J. Zhang, “Chat-REC: Towards Interactive and Explainable LLMs-Augmented Recommender System.” arXiv, Apr. 03, 2023. doi: 10.48550/arXiv.2303.14524.
[6] C. Wu, F. Wu, T. Qi, J. Lian, Y. Huang, and X. Xie, “PTUM: Pre-training User Model from Unlabeled User Behaviors via Self-supervision.” arXiv, Oct. 04, 2020. doi: 10.48550/arXiv.2010.01494.
[7] S. Geng, S. Liu, Z. Fu, Y. Ge, and Y. Zhang, “Recommendation as Language Processing (RLP): A Unified Pretrain, Personalized Prompt & Predict Paradigm (P5).” arXiv, Jan. 02, 2023. doi: 10.48550/arXiv.2203.13366.
[8] S. Rajput et al., “Recommender Systems with Generative Retrieval.” arXiv, Nov. 03, 2023. Accessed: Feb. 16, 2024. [Online]. Available: http://arxiv.org/abs/2305.05065