Cutting Edge Time Series Forecast Models
Time series forecasting is crucial because it helps us predict future events based on past data. This is important in many areas like business, where it helps in planning, or in weather forecasting, where it helps us prepare for future weather conditions. By understanding patterns in past data, we can make better decisions for the future. For example, a company might look at past sales data to predict future sales. Over time, the methods used for time series forecasting have become more advanced. Initially, traditional statistical methods were used, like ARIMA. Later, as technology improved, machine learning models were developed. These models could learn from data in more complex ways. Today, we have even more advanced models like N-Beats, N-HiTS, PatchTST, and TimeGPT, which use deep learning to make very accurate forecasts.
N-BEATS, NEURAL BASIS EXPANSION ANALYSIS FOR INTERPRETABLE TIME SERIES FORECASTING (2019)
N-Beats is a groundbreaking model in the field of time series forecasting. It stands out for its simplicity and effectiveness in predicting future data points based on past observations. Developed with a focus on deep learning, N-Beats has gained recognition for its ability to handle various forecasting tasks without the need for time-series specific components like trend or seasonality adjustments.
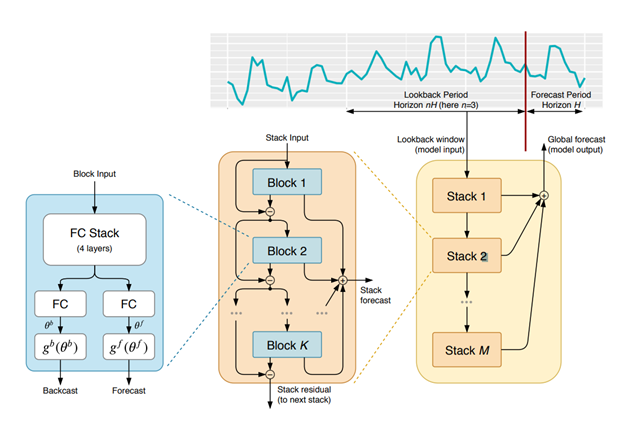
The architecture of N-Beats has several layers. The model is made up of several stacks (orange boxes). Each stack consists of several blocks (blue boxes). Each block (blue box) makes a partial prediction, and these are combined to form a stack (orange box). The model combines several stacks to make the final forecast for the future values.
Each block (blue boxes), the basic unit of the model, has four fully connected layers. It does two main things,
- It creates a ‘forecast,’ which is our prediction of future values. The ‘forecast’ output will be combined to form the final predictions.
- It generates a ‘backcast,’ a kind of reverse prediction that we compare with the input data to see how well the model is doing. The ‘backcast’ output will be the input of the next block.
Another important thing about N-Beats is its basis expansion, which makes it interpretable. The basis expansion, denoted as g in the diagram, is a learnable function. It transforms the input data into some specific basis and the neural networks inside the blocks capture the expansion coefficients. The N-Beats becomes interpretable if we use a polynomial basis to represent the trend and use Fourier basis to represent the seasonality.
N-HiTS, Neural Hierarchical Interpolation for Time Series Forecasting (2022)
N-HiTS builds upon the N-BEATS model to make it better at predicting and faster to compute. It does this by looking at the time series data in various ways, focusing on both quick changes and long-term trends. During prediction, N-HiTS mixes these different perspectives together. It takes into account both immediate changes and longer-term patterns. This process, known as hierarchical interpolation, helps the model give more accurate forecasts by considering all aspects of the time series.
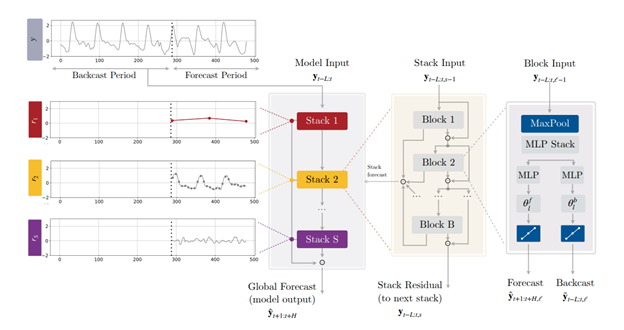
Looking at the image, it’s clear that this model closely resembles N-BEATS. Like N-BEATS, it generates both a forecast (future prediction) and backcast (comparison against past data), and is structured using stacks and blocks. The overall prediction it makes is a combination of the smaller predictions from each stack. Additionally, there are residual connections linking each block within a stack, further aligning it with the N-BEATS model’s design.
Compared to N-BEATS, the novelty of N-HiTS mainly relies on “multi-rate signal sampling”. At the input to each block, N-HiTS use a MaxPool layer to sample the inputs with a specific scale. A larger kernel in the MaxPool layer will force the model to focus on low-frequency/large-time-scale components (e.g. long-term trend). A smaller kernel in the MaxPool layer will force the model to focus on high-frequency/small-time-scale components. In this way, we force the different blocks to focus on different time-scale patterns.
When N-HiTS make predictions, unlike N-BEATS, N-HiTS predicts in different time-scale in different stacks as well. This is called “hierarchical interpolation”.
A big advantage of “multi-rate signal sampling” and “hierarchical interpolation” is that they greatly reduce the computation load. With a sampling-rate of k, the “hierarchical interpolation” in each stack or the “multi-rate signal sampling” in each block reduce k times of the output / input neurons in the network.
PatchTST, A TIME SERIES IS WORTH 64 WORDS, LONG-TERM FORECASTING WITH TRANSFORMERS (2022)
Unlike N-BEATS and N-HiTS, which are MLP based models, the PatchTST is a transformer-based model. The transformer, is a type of architecture initially popularized in natural language processing, now adeptly adapted for time series data. PatchTST is particularly recognized for its effectiveness in long-term forecasting, marking a significant shift from traditional models that often struggled with such tasks.
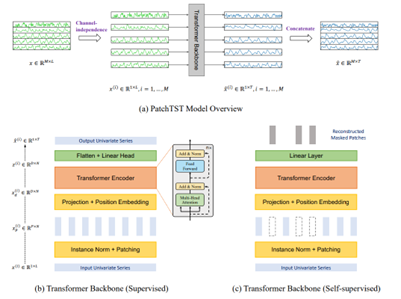
Transformers need a sequence of tokens as input. To fulfill this requirement, PatchTST utilizes the concept of ‘patching’ in time series data. This approach involves dividing the input data (time series) into smaller segments or ‘patches’, allowing the model to focus on local patterns within each segment. These patches are then processed through a transformer network, which is adept at capturing complex relationships in data. The transformer network in PatchTST is designed to handle these patches efficiently, enabling it to analyze longer sequences of data without a significant increase in computational complexity.
Note that a multivariate time series is considered as a multi-channel signal. Each channel is processed independently through patching and transformers. After that, the channels are concatenated.
Like transformer models in NLP, PatchTST can be trained through both supervised learning and self-supervised learning as well. In the supervised learning, the target output is the forecast period. To do the self-supervised learning, PatchTST masks several randomly selected patches and set to zero, and the model targets to reconstruct the masked patches.
TimeGPT (2023)
Drawing inspiration from the success of large language models in natural language processing, TimeGPT adapts the pre-training techniques to the time series forecast. It stands out for its ability to handle a wide range of forecasting tasks.
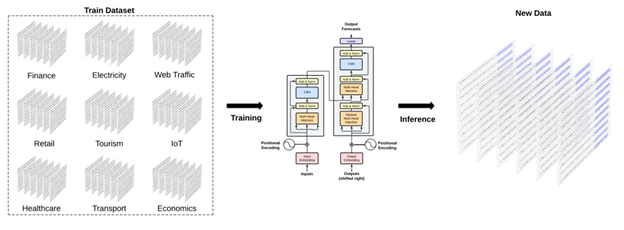
TimeGPT is another transformer-based model. The model itself is not new. The significance of TimeGPT stands on its vast training dataset of time series from various domains, allowing it to learn a wide array of temporal patterns. The model is designed to perform zero-shot inference, meaning it can make accurate predictions on unseen data without the need for retraining.
Implementations
With the help of nixtla.neuralforecast, we can easily implement these time series forecast models.
This is the minimal example of N-BEATS, N-HiTS, and PatchTST. To view more comprehensive usage examples, e.g. hyperparameter tuning, please check the Nixtla’s repository (https://github.com/Nixtla).
!pip install neuralforecast
from neuralforecast.utils import AirPassengersDF
from neuralforecast import NeuralForecast
from neuralforecast.models import NBEATS, LSTM, NHITS, PatchTST
Y_df = AirPassengersDF # Defined in neuralforecast.utils
models = [
PatchTST(h=horizon, input_size=104, patch_len=24, stride=24, max_steps=100),
NHITS(h=horizon, input_size=2 * horizon, max_steps=100),
NBEATS(input_size=2 * horizon, h=horizon, max_steps=100)
]
nf = NeuralForecast(models=models, freq='M')
nf.fit(df=Y_df)
Y_hat_df = nf.predict()
References
Oreshkin, B. N., Carpov, D., Chapados, N., & Bengio, Y. (2019). N-BEATS: Neural basis expansion analysis for interpretable time series forecasting. arXiv preprint arXiv:1905.10437.
Challu, C., Olivares, K. G., Oreshkin, B. N., Ramirez, F. G., Canseco, M. M., & Dubrawski, A. (2023, June). Nhits: Neural hierarchical interpolation for time series forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 37, No. 6, pp. 6989-6997).
Nie, Y., Nguyen, N. H., Sinthong, P., & Kalagnanam, J. (2022). A time series is worth 64 words: Long-term forecasting with transformers. arXiv preprint arXiv:2211.14730.
Garza, A., & Mergenthaler-Canseco, M. (2023). TimeGPT-1. arXiv preprint arXiv:2310.03589.