The common patterns behind Stable Diffusion, DALL-E, Imagen
Overview of the recent image generation models
The best image generation model today basically consists of three components: a text encoder, a generation model, and a decoder. These three modules are typically trained separately, then combined for inference. Most state-of-the-art text-to-image models you see today generally follow this approach.
- The text encoder transforms textual input into a series of vectors, providing a mathematical representation that can be processed by the model. Typically, the encoder can be well-known models, like GPT or BERT.
- The generation model utilizes this output along with a noise input, represented as vectors, to generate an intermediate output. This output could be a small, blurred image that can be understood visually, or it could be something indistinguishable.
- Lastly, the decoder is applied, which functions to restore the compressed image back to its original form. The decoder can be the second half of the auto-encoder and be pretrained separately as well.
Stable Diffusion
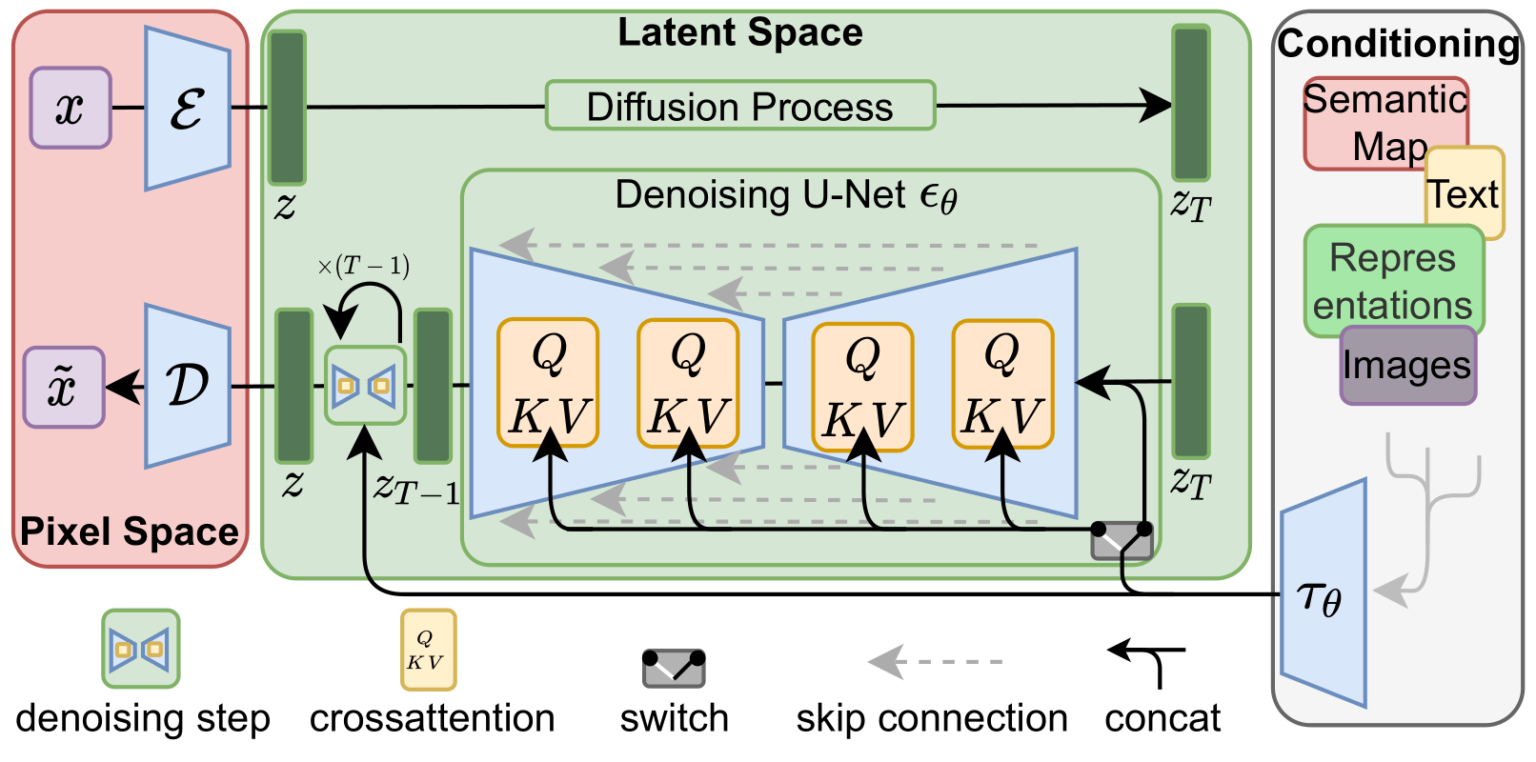
The Stable Diffusion paper provides an excellent illustration of an image generation model (Figure below). It starts with an encoder that processes the input, which can vary but is text in this instance. This step is followed by a generator model, which in the context of Stable Diffusion, specifically uses a Diffusion model. The final component is a decoder, which takes the compressed image - an intermediate product of the Diffusion model - and restores it to its original form. These three components - the encoder, generator model, and decoder - form the core framework of this image generation model.
DALL-E
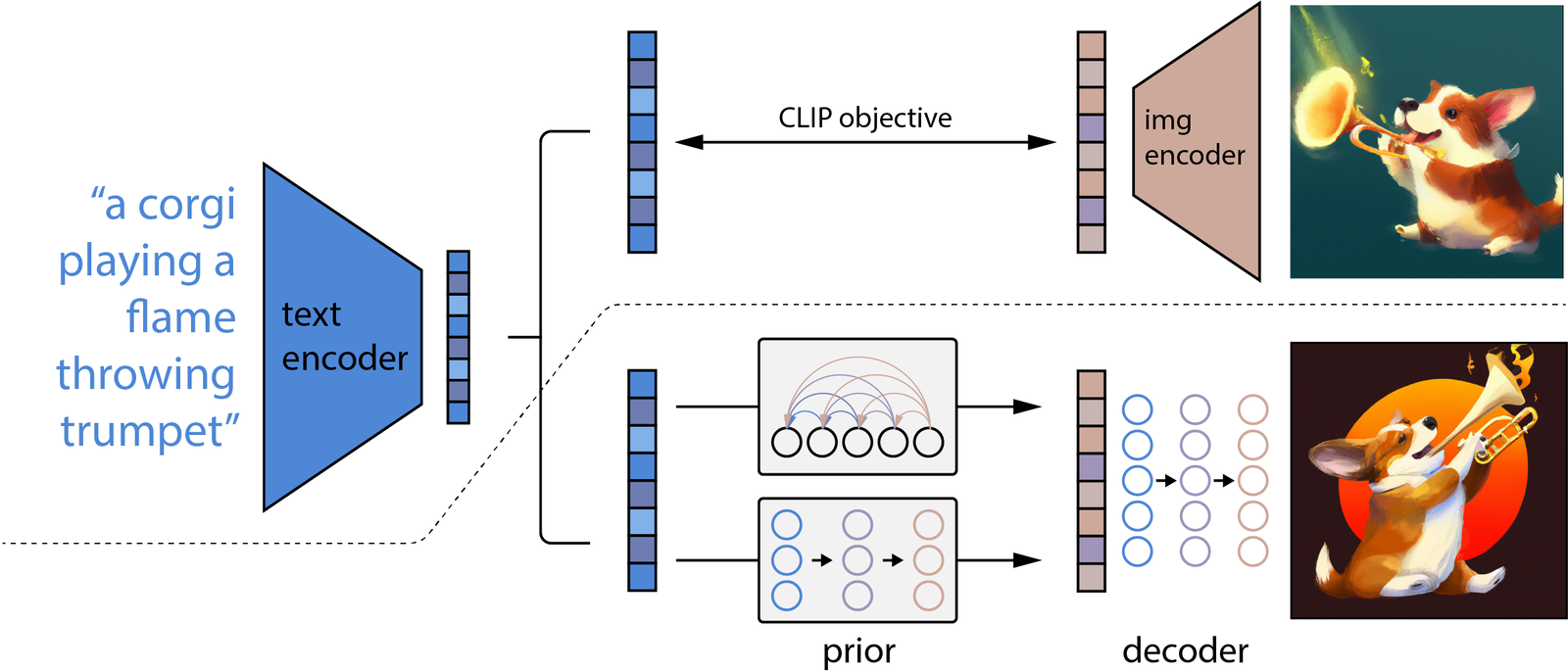
The DALLE series utilizes a similar process to the one previously discussed. It begins with a text encoder to interpret the input text. This is followed by a generation model; interestingly, DALLE incorporates two types of such models. One option is the Auto Regressive model, which becomes particularly useful after some initial processing. While this model may not be ideal for generating complete pictures due to its extensive computational requirements, it can effectively create a compressed version of an image. Alternatively, a Diffusion model can also be employed for this purpose. The final step involves a decoder, which restores the compressed image back to its original form. This tripartite structure of the text encoder, generation model, and decoder constitutes the backbone of the DALLE series.
Imagen
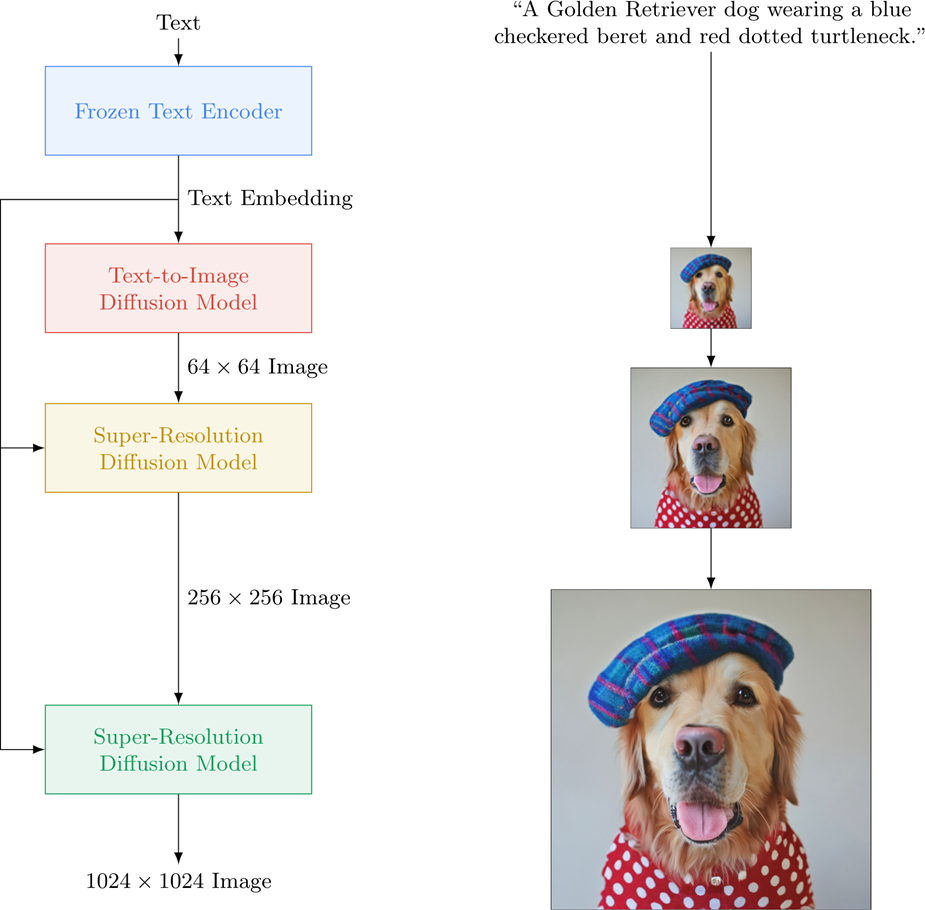
Google’s image generation model, Imagen, utilizes a similar process. It begins with a text encoder that transforms a piece of text into an understandable format. The next stage involves an image generation model that creates a compressed or smaller version of the image from the encoded text. Imagen’s process stands out in its comprehensibility; it initially generates a smaller, 64x64 pixel image, despite the end goal being a larger 1024x1024 pixel image. The final step is a decoder, also a Diffusion model in this case, which scales up the small image to produce a larger version. This, in essence, is the working process of Google’s Imagen model.
References
https://arxiv.org/abs/2112.10752
https://arxiv.org/abs/2204.06125
https://arxiv.org/abs/2102.12092
https://arxiv.org/abs/2205.11487