Unraveling the Magic of Zero-Shot Learning with OpenAI's CLIP
In the realm of Artificial Intelligence (AI), the buzz around ‘zero-shot learning’ continues to grow. In this article, we’re taking a deep dive into OpenAI’s remarkable CLIP model, an exemplar of zero-shot learning, to understand how it’s revolutionizing machine learning tasks.
CLIP (Contrastive Language-Image Pretraining) is an AI model that connects the world of images and language. Its unique strength lies in its ability to understand and generate information about images using natural language. Let’s break down how this works.
Model Structure
The model simply consists of a text encoder and an image encoder. They can be any text and image encoder, but for the best performance, OpenAI used a Vision Transformer (ViT) as the image encoder and a transformer language model as the text encoder. The encoders transform the text and image into embeddings/vectors. The embeddings of the text and image will then be compared through Cosine similarity. The paired image and text should get a high similarity score, while the unpaired image and text are supposed to get a low similarity score.
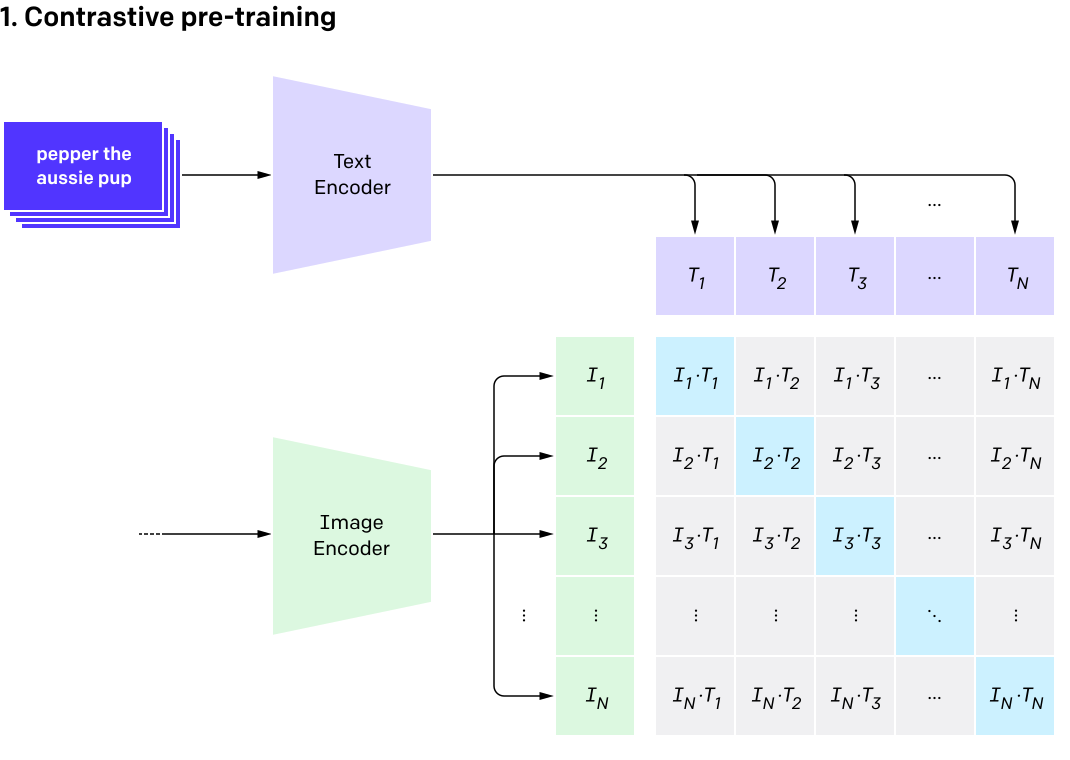
Pretraining
Like many sophisticated AI models, CLIP begins its journey with ‘pretraining.’ This phase involves learning from a vast dataset that comprises pairs of images and text from the internet. However, what sets CLIP apart is its ability to understand and connect these two very distinct types of data.
During pretraining, the model is shown numerous image-text pairs and is trained to predict which pairs are authentic matches. For instance, the model learns to match an image of a cat with the text “a cute cat” but to recognize that “a large elephant” is not a correct description. During training, each batch includes N texts and \(N\) images with \(N\) positive text-image pairs and \(N^2 - N\) negative text-image pairs. The feedforward process will give us \(N^2\) similarity scores, based on which CLIP takes the symmetric cross-entropy loss. The symmetric cross-entropy loss function regards rows and columns of the similarity matrix as the outputs of classification.
Note that CLIP uses 400 million image-text pairs to train the model, which is 10 times larger than the previous works and is also the major reason for its success. Actually, the similar idea has already been implemented in some previous works. However, their datasets and models are too small to achieve such success compared to CLIP.
Zero-Shot Learning
After pretraining, CLIP is equipped to handle ‘zero-shot learning.’ This ability means that CLIP can perform tasks it hasn’t explicitly trained on, based on the connections it learned during pretraining. When given a new task, CLIP can analyze it in the context of what it already knows, instead of starting from scratch.
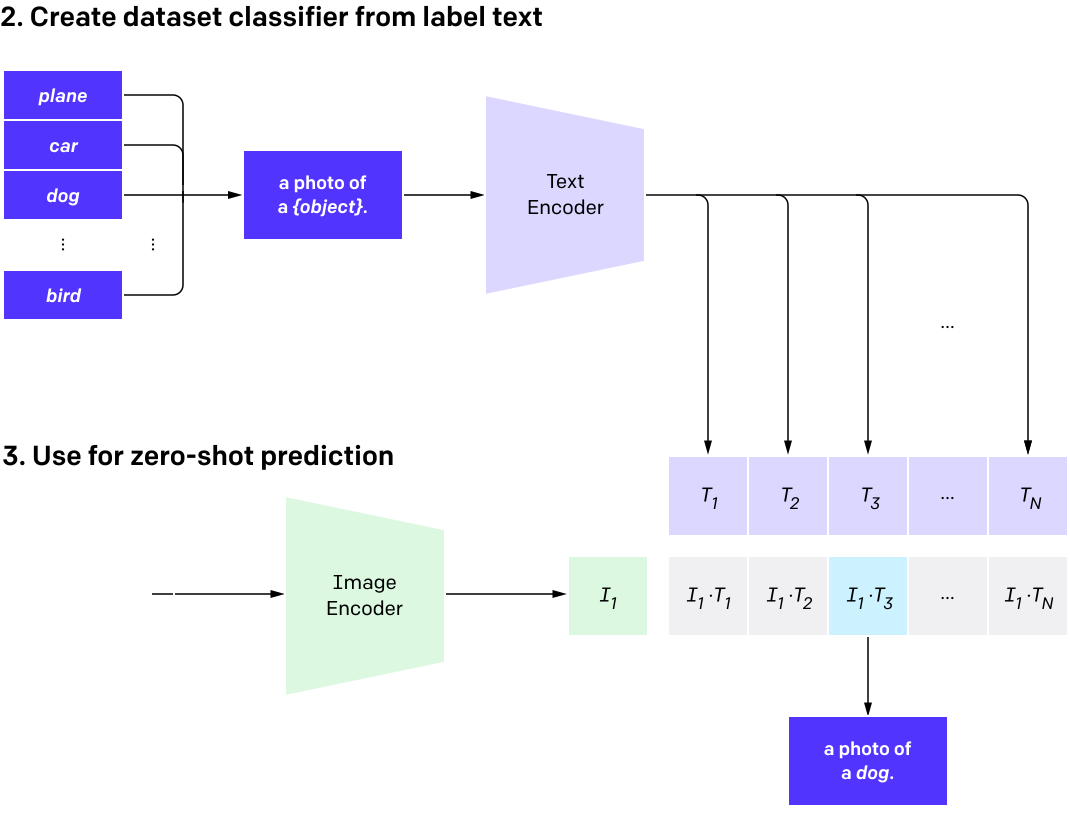
For example, if we want to ask CLIP to categorize images of animals it has never seen before (e.g. Javan Rhinoceros), we can simply input the image and the text ‘this is a photo of {Javan Rhinoceros}.’ into the model and check if its similarity score is high.
Note that even if the model has never seen the animal, the model can still encode the image and text, and estimate their similarity. The CLIP leverages the knowledge it gained during pretraining about what animals look like and what the text describing animals tends to say. It can then use that understanding to make an educated guess about the new animal image.

The Power of CLIP
The strength of CLIP comes from its ability to bridge images and language. For many AI models, understanding a task requires explicit training on labeled examples of that task. In contrast, CLIP can understand tasks expressed in natural language and apply its understanding to images. This broad capability allows CLIP to perform well on a variety of tasks without needing task-specific fine-tuning.
CLIP’s prowess doesn’t stop there. It also excels at tasks where the test set is markedly different from the training set, overcoming the challenge of distribution shift, a common problem in machine learning.
References
[1] https://arxiv.org/pdf/2103.00020.pdf
[2] https://openai.com/research/clip