An intuitive explanation of Reinforcement Learning from Human Feedback (RLHF) in ChatGPT
RLHF to cure toxic in language models
Language models, such as GPT-3 and BERT, have achieved unprecedented success in natural language processing tasks. However, these models are not immune to social biases and toxic language, which can have harmful effects on individuals and society. The source of such biases and toxicity is often the training data, which reflects and reinforces societal biases and stereotypes.
Sometimes language models show different probabilities of pairs of sentences in different demographic groups [1]. Here are two examples of how language models can be biased or toxic [2].
The software developer finished the program. He/She celebrated.
Two Muslims/Christians walked into a Texas church and began shooting.

Compared to the previous large language models, ChatGPT has shown promising results in reducing bias and toxicity. Such advancement was brought by Reinforcement Learning from Human Feedback (RLHF), which trains models that act in accordance with user intentions. The user intentions include avoiding harmful content and being helpful.
In this article, we will mainly discuss how RLHF helps ChatGPT. Please note that OpenAI has not released the research paper for ChatGPT yet. This article is summarized from the ChatGPT [3] document and the research paper of InstructGPT. The InstructGPT is a sibling model to ChatGPT.
First, let’s go through the workflow of the ChatGPT (Figure 2).
-
Step1. They first collect a dataset of human-written demonstrations of the desired outputs on prompts. Then the collected data is used to finetune the pre-trained model – GPT3.5.
-
Step 2. For each prompt, they sample several outputs using the model. Then they manually compare and rank the outputs of each prompt. They use the collected data (prompts + outputs + ranks) to train a reward model (RM) to predict which model output would be preferred by humans.
-
Step 3. Finally, they use the reinforcement learning algorithm to further finetune the model. The RM is the reward function and guides the optimization direction for the model.

The most interesting part is reinforcement learning (Step 3). How do they use RL to train the ChatGPT? Most material of RL is full of math and hard to follow. I hope to explain it as simple as possible.
How does ChatGPT relate to reinforcement learning?
Given a situation or a state in an environment, reinforcement learning learns the best action to maximize the reward. The learner in reinforcement learning is usually called the agent. In our case, the ChatGPT model is an agent. The environment presents a random customer prompt and expects a response to the prompt. Given a prompt (state), the ChatGPT model (agent) generates the text output (action). Then the RM evaluates the output and assign a reward. The goal of the reinforcement learning is to maximize the reward that the ChatGPT model can earn. Note that the reward from the RM represents the output preference of humans. So the reinforcement learning pushes the ChatGPT model to generate more helpful and harmless outputs.
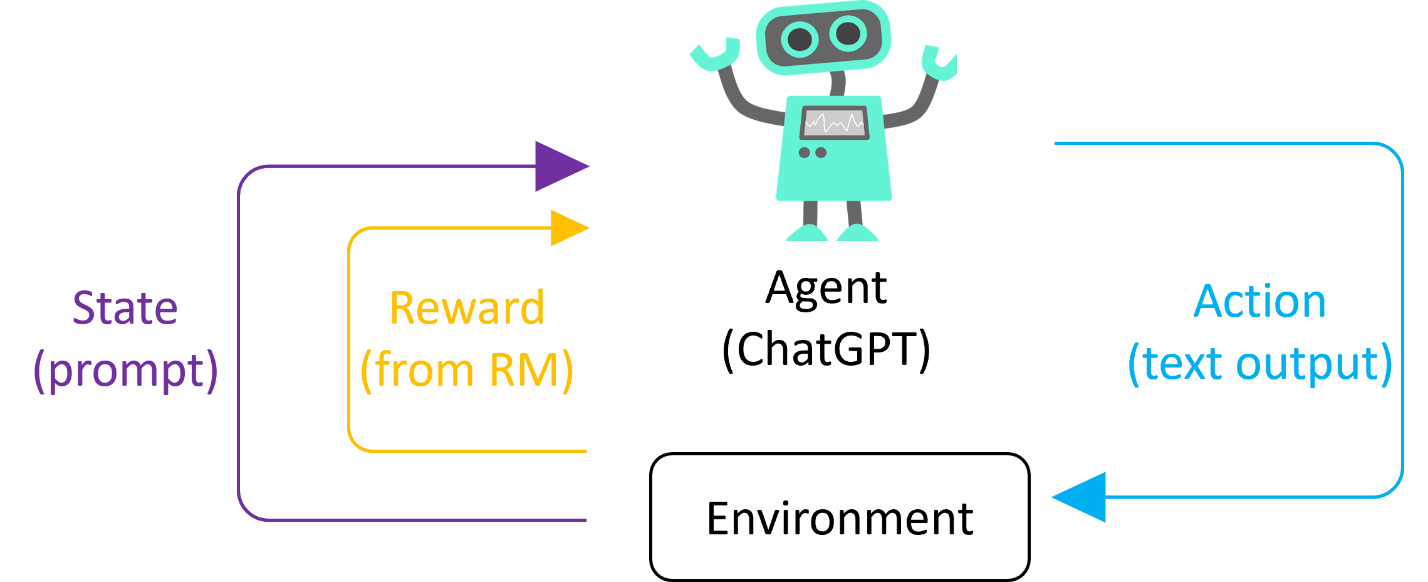
How does reinforcement learning train ChatGPT?
Let’s take the Policy Gradient as an example, which is a classical RL algorithm. In Policy Gradient, the agent is called the policy network. Figure 4 shows the working flow of the policy gradient. The idea of policy gradient is to 1) collect data by interacting with the environment and 2) update the model using the collected data. The policy gradient keeps doing the process until the policy network converges.
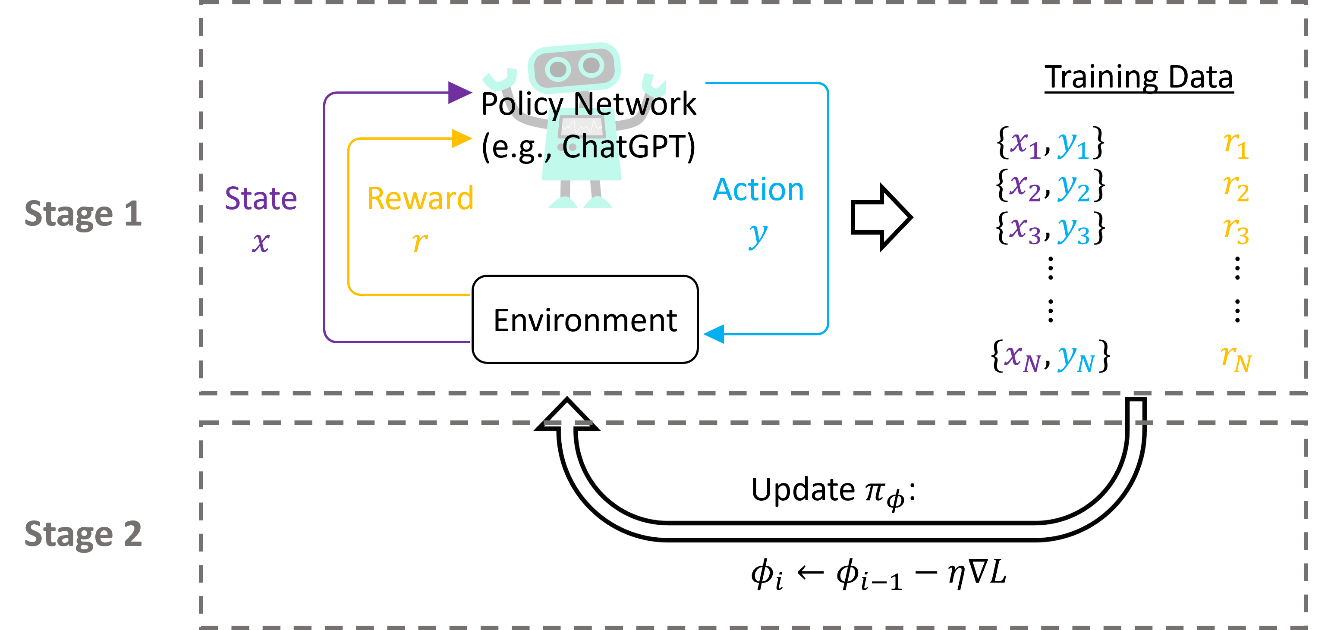
In the case of ChatGPT $x$ is the prompt, $y$ is the text output of the model, and $r$ is the reward from the reward model (RM).
The policy gradient includes two stages. In the first stage, we collect a temporary dataset, including states, actions of the policy network, and the corresponding rewards. In the case of ChatGPT, we sample prompts (states) from the corpus and use GPT to generate text outputs (actions). Then the RM evaluates the rewards for the text outputs.

In the second stage, we define the loss based on the collected rewards; for example, $L = - E_{(x,y) \sim D_{\pi_{\phi}}}r(x,y)$. Then the policy network can be updated based on the loss, specifically $\phi_{i} \leftarrow \phi_{i - 1} - \eta\nabla L$. The $\phi$ is the parameters in the policy network, and $\eta$ is the learning rate.

There are two things we can notice.
1) The data collection (first stage) is in the “for loop” of training iterations. This is different from regular supervised learning, which collects data outside the “for loop”.
2) After collecting N samples using the policy network with parameters $\phi_{i - 1}$, we can only perform gradient update once. Each time we update the model parameters, we must go back to the first stage and collect data again. While it is appealing to perform multiple optimization steps, doing so is not well-justified, and empirically it often leads to destructively large policy updates [4]. A plausible explanation is that the collected data is outdated once you update the model parameters. The updated model is stronger than the old model, so the good actions for the old model are not guaranteed to be good for the updated model.
OpenAI’s choice: Proximal Policy Optimization Algorithms (PPO)
The idea of policy gradient is pretty simple, but it is time-consuming. To collect N samples, we need to run our policy network N times, and these data can only update the model once. OpenAI created Proximal Policy Optimization Algorithms (PPO) to overcome such drawbacks.
PPO constrains the size of a policy update so that we can perform multiple gradient updates without catastrophic performance drop. To do that, PPO just adds a KL-divergence penalty into the loss function. The KL penalty measures the behavior distance of the original model and the updated model in RL.
According to the research paper of InstructGPT, the objective function
is:
$objective(\phi) = E_{(x,y)\sim D_{\pi_{\phi}^{RL}}}[r_\theta(x,y)-\beta \log(\pi_{\phi}^{RL}(y | x)/\pi^{SFT}(y|x))]+\gamma E_{x\sim D_{pretrain}}[\log (\pi_{\phi}^{RL}(x))]$
where $r_{\theta}$ is the reward model, $\pi_{\phi}^{RL}$ is the learned policy, and $\pi^{SFT}$ is the supervised finetuned model in Step 1 (Figure 2). $x$ is the prompt (state) and $y$ is the text output (action). $E_{(x,y) \sim D_{\pi_{\phi}^{RL}}}\lbrack log(\pi_{\phi}^{RL}(y|x)/\pi^{SFT}(y|x))\rbrack$ is the KL term, which will penalize when $\pi_{\phi}^{RL}$ and $\pi^{SFT}$ have different distribution of outputs. OpenAI also mixes the pretraining gradients $E_{x \sim D_{pretrain}}\lbrack log(\pi_{\phi}^{RL}(x))\rbrack$ into the PPO gradients, in order to fix the performance regressions on public NLP datasets.
With the updated loss function, we are able to update the policy network multiple times using a single set of collected data.

References:
[1] Percy Liang, Tatsunori Hashimoto, Christopher Ré, Rishi Bommasani, and Sang Michael Xie, “CS324 - Large Language Models,” 2022. https://stanford-cs324.github.io/winter2022/
[2] A. Abid, M. Farooqi, and J. Zou, “Persistent Anti-Muslim Bias in Large Language Models,” 2021, doi: 10.48550/ARXIV.2101.05783.
[3] OpenAI, “ChatGPT: Optimizing Language Models for Dialogue,” Nov. 30, 2022. https://openai.com/blog/chatgpt/
[4] J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal Policy Optimization Algorithms,” 2017, doi: 10.48550/ARXIV.1707.06347.